In July 2024, while OpenAI basked in the glow of 1.7 billion monthly visitors to ChatGPT, a relatively unknown Chinese entrepreneur made a bold prediction during an interview with 36Kr. He stated, “More investment does not necessarily lead to more innovation… OpenAI is not a god, nor can it always stay ahead.” At the time, the statement seemed like wishful thinking. Fast forward to January 2025, and those words have become a prophetic reality centered around DeepSeek R1. This new model sent shockwaves through Wall Street, proving that massive budgets are no longer the sole predictor of AI dominance.
During the World Economic Forum in Davos, American tech giants expressed confidence in their year-long lead over Chinese competitors. Ruth Porat, CFO of Alphabet, noted that while the U.S. was ahead, maintaining that lead was uncertain. However, few predicted the speed of the disruption that would follow just days later. On January 20, 2025, the same day Donald Trump was inaugurated, the Chinese startup DeepSeek launched DeepSeek R1, a logical reasoning AI that rivaled OpenAI’s most advanced systems at a fraction of the cost.
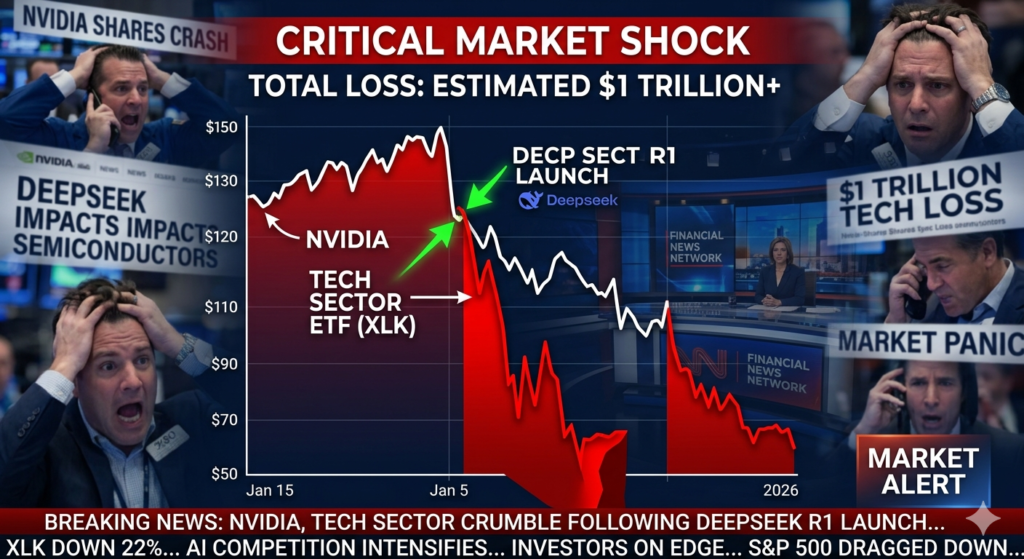
The result was immediate and catastrophic for U.S. markets. Within days, American and European tech stocks lost a collective $1 trillion in value. NVIDIA alone saw $589 billion wiped off its market cap in a single day—the largest single-day loss in U.S. stock market history. This wasn’t just a market correction; it was a paradigm shift triggered by DeepSeek R1. The architect of this disruption? Liang Wenfeng, a mathematics prodigy who dared to challenge the “bigger is better” doctrine of Silicon Valley.
Executives reacting to the DeepSeek R1 launch causing a stock market crash versus Chinese developers innovating.
Who is Liang Wenfeng? The Visionary Behind DeepSeek R1
To understand the DeepSeek R1 phenomenon, one must first understand its founder. Liang Wenfeng, born in 1985 in Zhanjiang, Guangdong, is the son of an elementary school teacher. His upbringing in a modest family instilled a deep respect for education, leading him to study calculus independently during middle school. His academic brilliance earned him a spot at the prestigious Zhejiang University, where he began developing AI algorithms to identify stock market patterns years before it became mainstream.
In 2008, amidst the global financial crisis, Liang and two classmates entered the Chinese stock market with zero prior experience. By 2015, they had founded High-Flyer, a quantitative trading fund that leveraged machine learning to analyze market data. At its peak in 2021, High-Flyer managed over 90 billion yuan ($12.4 billion). Although the fund later faced setbacks, managing around $8 billion today, it provided Liang with the capital and computational infrastructure to pursue his true vision: democratizing AI through models like DeepSeek R1.
Liang’s strategy was unconventional. While other investors focused on short-term returns, Liang began aggressively purchasing thousands of NVIDIA GPUs as early as 2019. When asked why, he famously compared buying chips to buying a piano: “I can afford it, and I have a group of people who desperately want to play it.” This foresight allowed High-Flyer to amass a computing cluster of over 10,000 advanced chips just as the Biden administration began tightening export restrictions on high-end hardware to China. You can read more about these US-China chip restrictions here.
Liang Wenfeng, the founder of DeepSeek R1, inspecting NVIDIA GPU clusters.
The Strategy That Powered DeepSeek R1: Talent and Efficiency
Liang founded DeepSeek in 2023 in Hangzhou, China’s tech hub, with a clear mission: to break the monopoly of major tech firms by relying solely on Chinese talent. Unlike Western giants that recruit globally, DeepSeek’s team consists entirely of local researchers, many of whom are fresh graduates from top institutions like Peking University and Tsinghua University. For more insights into our previous analysis of global tech talent shifts, check out our article on the Global AI Talent War.
This approach was strategic. A 2024 study by MacroPolo revealed that China had surpassed the U.S. as the world’s largest producer of AI talent, accounting for nearly 50% of top AI researchers globally. Liang capitalized on this shift, offering competitive salaries that rival ByteDance (TikTok’s parent company). Moreover, he deliberately hired inexperienced employees, believing that “experience can sometimes be an obstacle.” He argued that experts often rely on fixed methods, whereas newcomers are forced to innovate and think critically to solve problems.
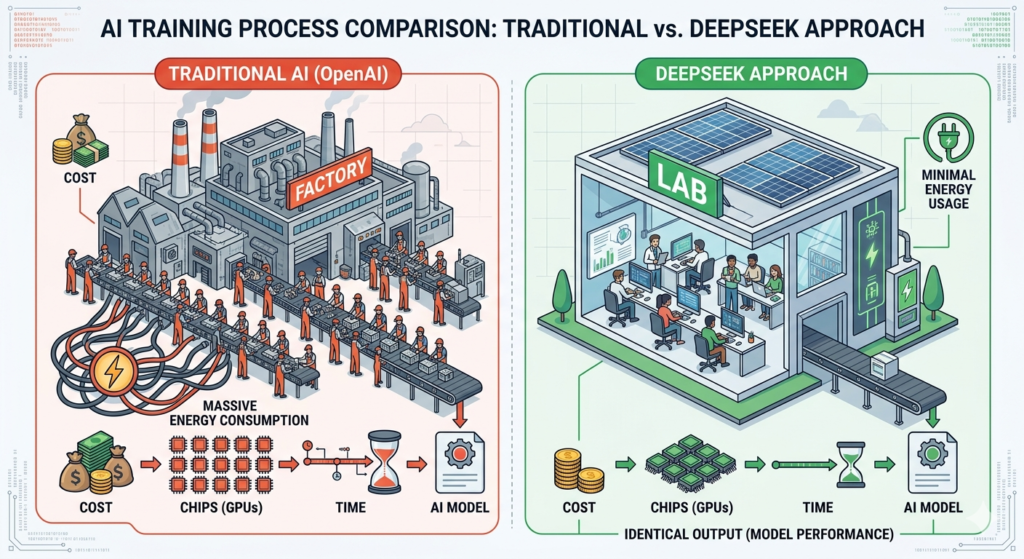
DeepSeek’s commitment to open-source development further differentiated it from competitors. While companies like OpenAI and Google guard their models behind paywalls and APIs, DeepSeek released its models freely, aiming to democratize access to advanced AI. This philosophy culminated in the release of DeepSeek V3 in late December 2024, a model with 671 billion parameters trained in just two months using only 2,048 chips at a cost of $5.6 million. In stark contrast, OpenAI’s GPT-4, with 1.8 trillion parameters, required over 16,000 chips and cost an estimated $100 million to train. This efficiency paved the way for the breakthrough performance of DeepSeek R1.
Comparison chart showing the cost efficiency of DeepSeek R1 training versus traditional US models.
DeepSeek R1: The Model That Broke the Market
The true earthquake arrived on January 20, 2025, with the official launch of DeepSeek R1. This logical reasoning model was designed to compete directly with OpenAI’s o1 (formerly Q), which costs users $200 per month. DeepSeek claimed DeepSeek R1 not only matched but in some benchmarks exceeded o1’s performance in math and coding tasks, all while being completely free.
Shortly after, DeepSeek unveiled Janus Pro, a compact image-generation model capable of running on standard laptops, which the company claimed outperformed OpenAI’s DALL·E 3. These releases shattered the industry’s long-held belief that superior AI requires massive, expensive infrastructure. DeepSeek R1 proved that smart architecture could trump brute force.
How Mixture of Experts Made DeepSeek R1 Possible
How did DeepSeek R1 achieve such efficiency? The answer lies in its innovative use of the Mixture of Experts (MoE) architecture. Traditional models like GPT-4 act as a “librarian” who reads every book in the library to answer a question—a process that is computationally expensive and slow. DeepSeek R1, however, was trained to be a “specialized librarian” that knows exactly which book to consult for a specific query.
In the MoE framework, the model consists of multiple “expert” sub-networks, each specialized in a different domain (e.g., math, physics, literature). When a query is received, a routing mechanism activates only the relevant experts, significantly reducing the computational load. For instance, while DeepSeek R1 has 671 billion parameters, it activates only 37 billion per forward pass, making it incredibly fast and cost-effective. This approach allowed DeepSeek to train powerful models with limited resources, bypassing the need for the massive chip clusters that Western companies rely on. According to a report by the Wall Street Journal on the market impact, this efficiency is what terrified investors.
Diagram illustrating the Mixture of Experts architecture powering DeepSeek R1 efficiency.
The Aftermath: A $1 Trillion Wake-Up Call for NVIDIA
The market reaction to DeepSeek R1’s success was swift and brutal. Investors realized that if high-performance AI could be built cheaply, the massive capital expenditures by companies like NVIDIA, Microsoft, and Google might be unsustainable. The narrative of “AI scarcity” collapsed overnight.
On January 27, 2025, NVIDIA’s stock plummeted by nearly 17%, erasing $589 billion in value. The broader tech sector followed suit, with the S&P 500 and Nasdaq experiencing significant drops. The Wall Street Journal described the event as a “bloodbath,” reflecting the panic among investors who had bet heavily on the idea that AI dominance required unlimited spending. While some analysts speculated about a coordinated Chinese government message to the Trump administration, the reality is simpler: DeepSeek R1 exposed a flaw in the industry’s logic. As Lennart Heim of the RAND Corporation noted, DeepSeek didn’t just build a better model; it built a smarter one.
Stock market crash graph triggered by the release of DeepSeek R1 affecting NVIDIA shares.
The Future of AI: Can the U.S. Compete with DeepSeek R1?
Despite the shock, the race is far from over. Operating advanced AI models remains expensive, and giants like Google and OpenAI continue to invest billions in R&D. However, DeepSeek R1 has fundamentally altered the landscape. It has proven that innovation is not synonymous with expenditure. Smaller, agile teams with novel architectures can now compete with established behemoths.
For the U.S., the challenge is twofold: maintain its lead in cutting-edge research while adapting to a new reality where cost-efficiency is paramount. For the rest of the world, including emerging markets in the Middle East, the success of DeepSeek R1 offers a glimmer of hope. It demonstrates that with the right talent and creative problem-solving, even resource-constrained regions can participate in the AI revolution.
As Liang Wenfeng and his team prepare for the next version of DeepSeek, one thing is certain: the era of unchecked AI spending is over. The future belongs to those who can do more with less, a lesson clearly taught by DeepSeek R1.
Alt Text for Image:Global developers collaborating on AI innovations following the DeepSeek R1 breakthrough.
Conclusion
The rise of DeepSeek R1 and Liang Wenfeng is more than a business story; it is a testament to the power of ingenuity over resources. By challenging the status quo and leveraging local talent, DeepSeek has forced the global AI industry to rethink its strategies. As we move forward, the question is no longer “Who has the most chips?” but “Who has the smartest ideas?”
What do you think? Can Middle Eastern companies or other emerging markets replicate the success of DeepSeek R1? Or is the gap too wide to bridge? Share your thoughts in the comments below!
Disclaimer: This article is based on events and data available as of January 2025. Market conditions and technological landscapes are subject to rapid change.




Leave a Reply